







Gitを導入したい
本記事はGitを導入しようと思うが、コマンドラインに慣れていない、バージョン管理システムを使うのは初めてだという人向けに書きました。
また主に1人でGitを使うことを想定しています。あまり範囲が広いと理解が困難になるので、説明は1人で使うにあたって必要最低限の要件に収めているつもりです。
Gitとは
Gitは分散型バージョン管理システム
バージョン管理システムは開発の履歴を管理することができる仕組みのこと。
管理対象はどんな種類のプログラミング言語・プロジェクトでも構わないです(はず)。だからwebサイト開発(html,css,js,phpなど)だろうが、アプリ開発(swift,Ruby,python等)だろうが、組み込み開発(C/C++,java等)だろうが、会計システム開発(cobol等)だろうが管理可能ですよ。
バージョン管理システムでプロジェクトを管理すると、どこでどのようにどんな変更・修正が加えられたのかが整理され、前のバージョンに容易に戻ることもできるので効率よく、かつソースコードに混乱をきたさなくて済むようになっています。
Gitは分散バージョン管理システムと呼ばれます。Gitではリポジトリ(後述)からローカルにリポジトリクローンを得ることで作業を進める。開発者ごとにリポジトリが分散するので分散型と呼ばれる所以です。Gitは分散型であるからこその恩恵を受けやすいバージョン管理システムです。
Gitが作られた経緯
GitはLinuxのカーネル開発を効率的に行う為に生み出されました。もともとLinuxのカーネル開発には別なシステムバージョン管理システムが使われていたのだそうです。

しかし、既存のバージョン管理システムでは具合が悪かったようで、新たにバージョン管理システムを生み出す必要がでてきたようです。そこでLinuxの開発者であるリーナストーバル氏が新しいバージョン管理システムを開発するに至ります。
この辺の経緯はwikipediaに詳しくあるので参照をお勧めする。wikipedia Git
カーネル開発となるとプロジェクトも巨大で、もちろん1人ではできません。複数の凄腕たちがプロジェクトに参加することになります。 Linuxカーネル開発のようなオープンソース開発では全世界中に開発者がいることになります。
Gitは大人数で巨大なソースコードプロジェクトを効率的に共有する為に開発されたということになります。
カーネル開発というある意味最前線で稼働していること、GitHubなどのホスティングサービスが出現したこと、オープンソースであり個人での扱いやすさも相まって急速にGitの利用が広まったというのが現在の状況のようです。
Gitの概念
リポジトリの意味
リポジトリには倉庫とか保管所とかという意味があります。具体的にはファイル置場という解釈でよいかと思います。
Gitではさまざまな仕組みで履歴やファイルを格納してバージョンを管理する仕組みを提供しますが、それらは具体的にディレクトリ構造と複数の種類のファイルの関連性で実現されています。そのことをGitリポジトリというのです。
分散型の所以リモートリポジトリとローカルリポジトリ
Gitは分散型バージョン管理システムだと説明したが、その分散型について説明しておきたいと思います。
中央集権的な仕組みのバージョン管理システムではリポジトリは一つしか存在しません。開発者全員でそのリポジトリにアクセスすることになります。
普通このような共有するリポジトリはサーバー上などに設置されるので、リモートリポジトリと呼ばれます。リモートリポジトリはマスターのような扱いになります。
Gitの場合でもリモートリポジトリが存在するのは変わらないが、リポジトリのコピーをローカルにもってくることができます。そのコピー作業をクローンといい、ローカルにもってきたリポジトリはローカルリポジトリと呼ばれます。
ローカルリポジトリで各開発者が納得のいくまで作業ができるようになっており、マスターとなるリモートリポジトリを不用意に汚すことを回避できるようになっています。
リモートリポジトリへローカルリポジトリの内容を送る「プッシュ」
ローカルリポジトリで作業を進めることになるので、作業が進めば進むほど、リモートリポジトリとローカルリポジトリの内容には差異がでてきます。
Gitではローカルリポジトリの内容をリモートリポジトリに同期することができます。その操作の事をプッシュといいます。プッシュを行うとローカルリポジトリとリモートリポジトリは同じ内容になるという訳です。
リモートリポジトリの内容をローカルリポジトリに持ってくる「プル」
複数の開発者で作業を進めていると誰かがプッシュをしているかもしれません。だからリモートリポジトリの更新された内容をローカルに持ってくることもできます。その操作をプルといいます。
誰かがプッシュをすれば、リモートリポジトリには自分以外の人の変更点が付け加えられていることになります。その変更点をローカルにも取り込んでおかないと、開発の整合性が保てなくなってしまうかもしれません。
このようにGitではリモートリポジトリとローカルリポジトリの間でやり取りをしながら開発作業を進めていくことになります。
ローカルリポジトリだけも管理は可能だが…
ただ、1人で開発する場合はローカルリポジトリだけでもバージョン管理が可能です。1人しかいなければ共有するリモートリポジトリが必要ないからです。
しかしながらバックアップ的観点からしても、1人開発のときでもリモートとローカルの活用は有意義なことだと思います。
リポジトリの中身
リポジトリの実体はディレクトリとファイルだと説明しました。
Gitではリポジトリと作るとその場所に.gitというディレクトリが拵えられます。このフォルダの中にいろいろな情報やファイルがGitで定められている方法に従って格納されるようになっています。
Gitディレクトリの各ディレクトリもしくはファイルの大まかな意味を説明したのが以下です。作業を進めるとさらにファイルや各ディレクトリに子ディレクトリが出来たりします。(※以下はNetBeansIDEでjGitを使用した場合のディレクトリ・ファイル構成となります。Gitそのものとは若干構成が異なるかもしれない)
| 名前 | 種類 | 意味 |
|---|---|---|
| .git | ディレクトリ | ルートディレクトリ |
| branches | ディレクトリ | ブランチの情報を格納 |
| hooks | ディレクトリ | フックスクリプトを格納 |
| logs | ディレクトリ | リポジトリ操作のログを格納 |
| objects | ディレクトリ | Gitオブジェクトを格納 |
| refs | ディレクトリ | リファレンスを格納 |
| config | ファイル | リポジトリの設定要件 |
| index | ファイル | コミット予定のファイル表 |
| HEAD | ファイル | 現在の作業対象ブランチを示すhead |
Gitを使うようになれば追々調べたりすることになると思いますが、今の段階ではすべてのディレクトリやファイルの意味を理解しなくてもいいです。とりあえず大事だと思われる部分を説明していきたいと思います。
履歴やファイルそのものである「Gitオブジェクト」
Gitでは開発履歴やプロジェクトファイルをオブジェクトファイルとして格納します。そのことを総称してGitオブジェクトと言います。
Gitオブジェクトは4種類のみです。
| 名前 | 役割 |
|---|---|
| commitオブジェクト | 履歴情報をファイル化したもの。コミットという操作をすると作られます。 |
| Blobオブジェクト | プロジェクトファイルをBinary Large Objectという方式でファイルにしたものです。ステージングもしくはコミットという操作をすると作られます。 |
| Treeオブジェクト | ディレクトリ構造をファイル化したもの。コミットという操作をすると作られます。 |
| Tagオブジェクト | 名前付けに使うタグの情報をファイル化したもの。タグを制作すると作られます |
4種類しかないですが、これらのオブジェクトファイルの絶妙な関連性でうまいこと開発履歴が管理できるようになっているのです。
Gitオブジェクトが作られる操作
履歴を残す「コミット」
履歴を残す操作をコミットといいます。
開発作業が進むと区切りの必要性が出てきます。一定の作業量や、機能搭載の目途など履歴を残したほうがいいなというタイミングはいろいろな哲学があるみたいですが(なるべく整理されたコミットをすることが望まれる)、コミットすることはまさに履歴を残していくことに他ならないので、Gitを使う上でもっとも根幹をなす操作の一つです。
コミットでcommitオブジェクト(ファイル)が生成格納されます。また同時にTreeオブジェクトが生成格納されます。
コミットの準備「ステージング」
ステージングを行うとblobオブジェクト(ファイル)が生成格納されます(ステージングを行わずコミットした場合はコミット時にblobオブジェクトが生成格納される)。
コミットはステージングを行わなくとも直に行うことができますが、コミットの前にステージングする方が一般的なようです。
ステージングはコミットする予定のファイルをblobオブジェクトファイルにして、先にリポジトリへアップロードします。
また.gitディレクトリ直下のindexというファイルに、予定に上がったblobオブジェクトファイルのID(後述)が記述されます。
このindexファイルを確認することで、コミットを正確に行うことができるという訳です。「しまった今回のコミットに必要だったファイルを含めていなかった」などということを回避することができます。
Gitオブジェクトが格納されている場所
objectsディレクトリ
Gitオブジェクトはobjectsディレクトリに格納されます。各オブジェクトは基本的に英数字名のフォルダに一つのファイルが一つのオブジェクトとして格納されています。

Gitオブジェクトファイルの名前
各オブジェクトファイルには長い英数字の名前付けられています。この長いファイル名はファイルの内容を元にSHA-1という関数で計算され付けられます。
Gitオブジェクトのファイル名はIDやハッシュ値と呼ばれ、オブジェクトを一意に特定するために使われる。つまりファイル名がユニークになるというわけです。

この仕組みにより、内容が異なるオブジェクトファイルは同じIDになりません。逆に同じ内容のオブジェクトファイルはどこでオブジェクトが生成されても必ず同じIDになるようになっています。
履歴を形づくる「Gitオブジェクト」の役割
先ほどの章で簡単に各Gitオブジェクトの意味を紹介しましたが、もう少し詳しく見ていきたいと思います。
Gitオブジェクトの関連性
実はオブジェクトファイルを見ただけではどの種類のオブジェクトなのか見分けがつきません。ファイルを開いてみてもバイナリだから(バイナリエディタなどで見ないと)よくわからないのです。
ごちゃまぜに格納されているようなものです。見分けがつかないのにどのように整理をしているのでしょうか?
Gitオブジェクトは各個に与えられた役割により、他のオブジェクトと関連性を構築しています。これは別に難しいことではなく、ちょっとした伝言ゲーム的な管理方法になっています。前の章で説明したオブジェクトのIDが重要な要素を握っています。
まず重要なのがcommitオブジェクトです。前の章でcommitオブジェクトはコミットという操作で作られると説明しました。先に説明したとおりコミットとは履歴を残す操作のことです。
だからcommitオブジェクトがある時点での履歴そのものと言えます。commitオブジェクトファイルには以下のような事が書かれています。

そうcommitオブジェクトファイルにはコミットに関係しているオブジェクトファイルのIDが記載されているだけなのです。
頼りない感じがしますが、commitオブジェクトファイルの内容から、コミットに関係するTreeオブジェクトとBlobオブジェクトを特定することができるようになっているという寸法です。
commitオブジェクトと他のオブジェクトとの関連性を図にしてみました。

commitオブジェクトは自分の親の(前の)commitオブジェクトのIDを持っています。
そしてディレクトリ構造情報が書かれているTreeオブジェクトのIDを持っています。
さらにTreeオブジェクトはディレクトリとディレクトリに属するBlobオブジェクトファイルの情報持っています。
これでcommitオブジェクトは自分と連続性のあるcommitオブジェクトを辿ることができ、かつ自分に関係しているオブジェクトを特定することができるのです。
つまりcommitオブジェクト→Treeオブジェクト→Blobオブジェクトという参照の流れがGitの履歴管理の基本と言えます。IDが一意で定まるので危険なく単純な伝言ゲームで管理が出来てしまいます。
イメージとしてはツリー構造と捉えるといいかもしれません。

コミットがある時点での履歴、コミットのつながりが開発履歴の流れという事になります。重要な概念なのでしっかり理解できるようにしておきたいと思います。
開発ストリームを意味する「ブランチ」
ブランチの意味
Gitにはもう一つ重要な概念があります。それはブランチです。遅めの朝食のことではありません。綴りはbranchで意味は「分岐」です。Git上ではブランチを開発ストリームとします。
リポジトリを初期化し、最初のコミットがされるとmasterブランチが作られます。masterは元になる開発ストリームです。ブランチはコミットをぶら下げておく竿のようなものとイメージしてもらうといいかもしれません。

ブランチを作る
最初に説明したとおりブランチは分岐ということで、開発ストリームを分岐することができます。
ブランチは安全にかつスマートに日々の開発を進める為にも使えるので使用頻度の高い機能です。(ブランチという言葉は分割するという動詞的な意味で使われる場合も、ブランチされたストリーム自体を指すこともあるので注意)
 /p>
/p>
たとえばmasterブランチからnewブランチを分岐させたとします。分岐させた後はそれぞれのブランチで作業(コミット等)が進むので、互いのブランチに影響を与えません。

これを活用すればmasterブランチを汚さずに開発を進めることができます。
ブランチをマージする
分岐できるなら統合もできます。Gitではブランチを統合する際にはマージ(merge)という機能をつかいます。開発の流れを一本化するのです。

マージすると、それぞれのブランチでのコミットが共有されるようになります。例ではnewブランチでのコミットがmasterブランチと関連を持つようになります。(マージしてもnewブランチは別途削除の操作をしない限り無くなるわけではない)
マージしたことも履歴として残すべきなので、通常マージコミットというコミットが作られます。このマージコミット以前はmasterブランチもnewブランチも同じコミットを共有しているということになります。
マージ後のブランチの削除
マージした後にマージ元のブランチを削除してもコミットが失われることはありません。

現在位置を特定する「リファレンス」と「ヘッド」
いままでGitオブジェクトとブランチを説明してきました。今度は作業対象を指し示すリファレンス(reference)とヘッド(HEAD)についてです。
Gitでは多数のブランチやコミットが存在することになります。自分が今どこを対象に作業を行っているかわからなくなると大変です。その為の目印がリファレンスとヘッドなのです。
リファレンス
リファレンスとは各ブランチにひとつづつ存在する、ブランチの先頭のコミットを指し示す情報ファイルです。このファイルには単純に先頭のcommitオブジェクトのIDが記述されています。(正確に言うとフォルダ名+ID)
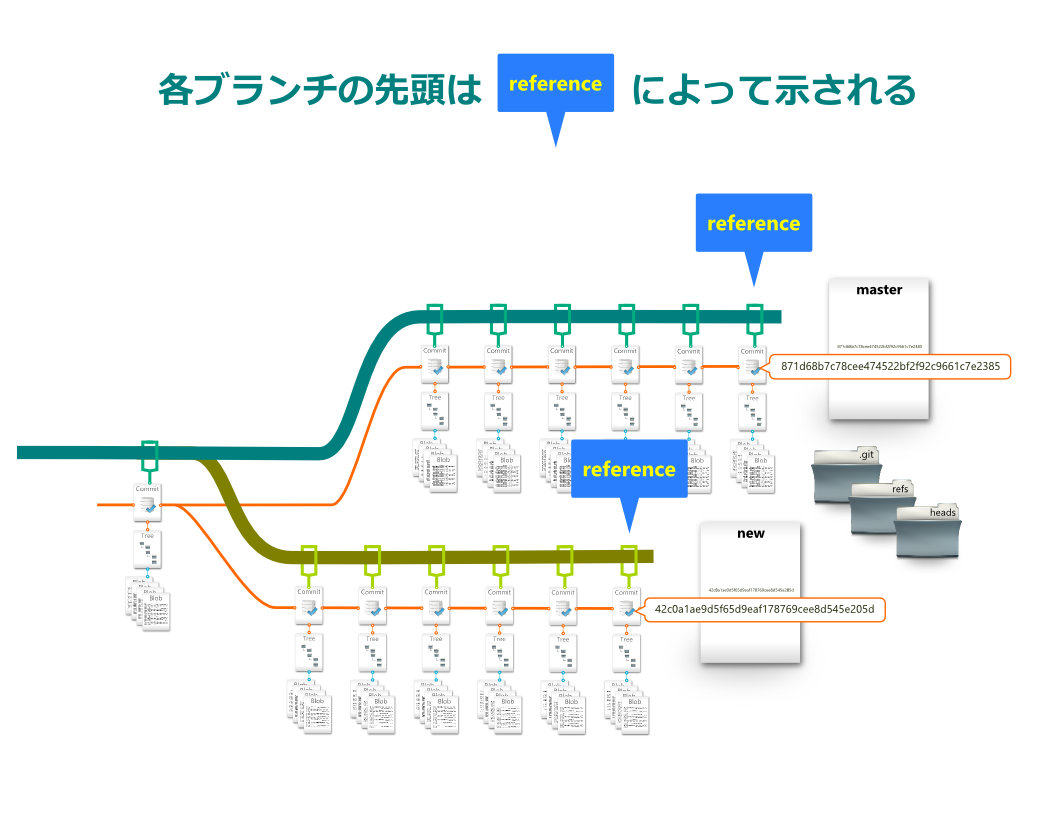
コミットがされる度にリファレンスファイルは書き換えられ、常にそのブランチの先頭コミットを指し示すようになっています。
リファレンスファイルは.git→refs→headsの中に、ブランチの名前がファイル名となって格納されています。

HEAD
さらにリファレンスを参照するHEADという特殊なリファレンスがリポジトリに一つ存在しています。HEADは現在の作業対象となっているブランチを指し示すリファレンスです。

HEADファイルは.gitディレクトリ直下にHEADというファイル名で格納されています。
具体的には作業対象のブランチのリファレンスを指し示しています。HEADファイルには単純にリファレンスファイルのパスが記述されているだけです。
作業しているブランチを切り替えることを「〇○ブランチにチェックアウトする」と言います。チェックアウトとするとHEADファイルはチェックアウト先のブランチのリファレンスを指し示すことになります。

リファレンスとHEADのおかげでどこが先頭か、今はどこが作業対象なのかが判るようになっています。
まとめ
振り返りしてみる
今回の記事について振り返ってみる
- Gitは分散型バージョン管理システムである
- GitはLiunxのカーネル開発の為に生み出された
- リポジトリとはファイル置場である。
- Gitリポジトリの実体は.gitディレクトリをルートとするディレクトリ構造とファイル群
- 開発履歴やプロジェクトファイルを意味するGitオブジェクトファイルは4種類
- Gitオブジェクトの名前はハッシュ値でIDとして活用される
- Gitオブジェクトはコミット・ステージングなどの操作で生成される
- commitオブジェクトは履歴そのもので、内容を辿ればそのコミットに関係するオブジェクトを特定することができる
- 開発ストリームをブランチとして分岐させる事が出来る
- 分岐後、コミットは各ブランチにて行われ関連性を持たない
- ブランチはマージ(統合)する事が出来る
- マージされた後のブランチは削除されてもコミットが消えることはない
- ブランチの先頭を指し示すのがリファレンス
- 作業対象のブランチを指し示すのがHEAD
ざっとGitの概念を説明してきた。最初にも言及したとおり必要最低限のつもりですが、実のところまだ言及したりない部分があります。Gitにはもっと多くの要素がありますが、実際に使ってみながらでないと説明しにくい点も多いです。
おそらく初めてGitに関するこの手の記事を読まれた方は「なんのこっちゃ」と思うところも多いのではないでしょうか?
厳密に言えば間違っている部分があるかもしれないので、鵜呑みにはしないでほしいですが、なるべく簡単に理解できるよう図をたくさん作る努力はしまシタ。
「なんのこっちゃ」が「なんだこのことか」に変っていただけたら嬉しいです。

